
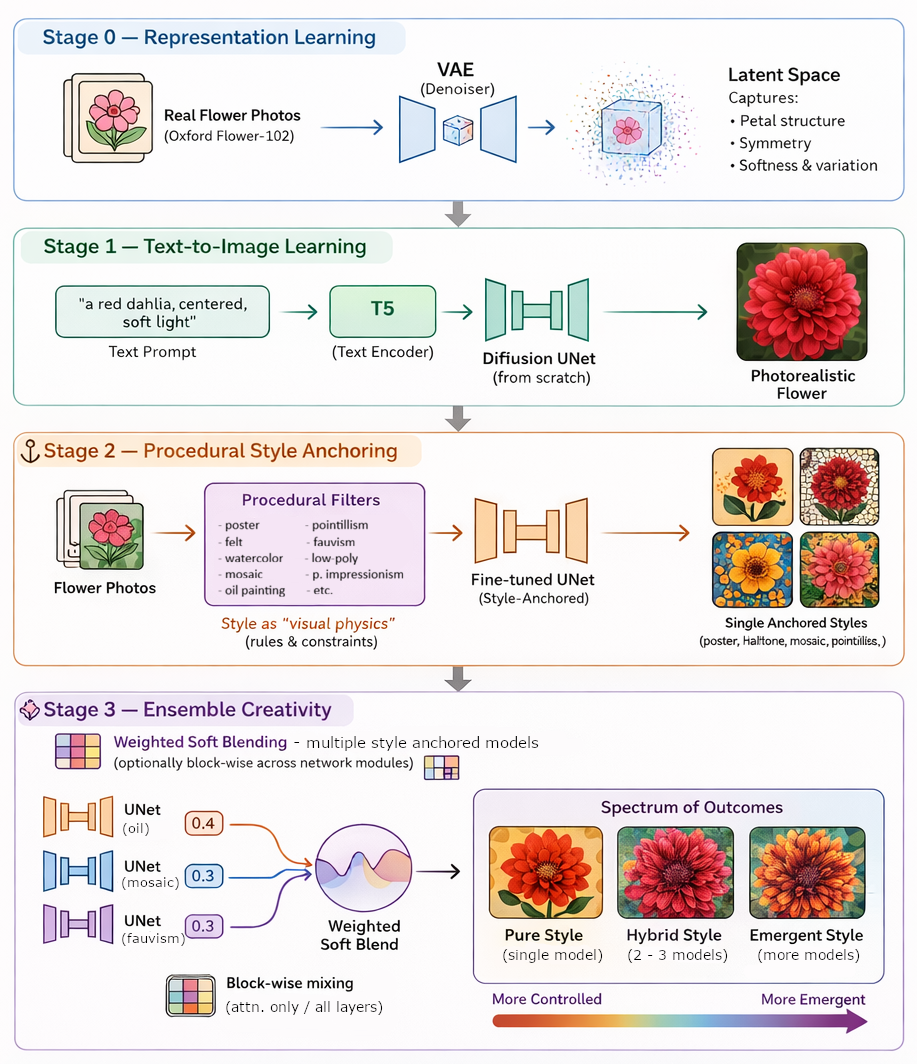
Current text-to-image models like Stable Diffusion are incredible, but they carry an inherent limitation: their stylistic range is strongly shaped by what they’ve encountered in large-scale training data, which can include copyrighted material. This creates:
This gallery presents flower images that look painted, printed, stitched, or some form of artistic stylized - yet the system that generated them was never trained on paintings, illustrations, or any art dataset. No pre-trained checkpoints of any art style / dataset as well.
Research Questions:
(1) How much can a generative model internalize a recognizable visual style from procedural supervision alone, without ever seeing human-made artworks?
(2) Can the ensemble of several models trained with procedural anchoring of different art style create some emerging, yet visually coherent art styles? ⤵ (click for more...)
To explore this, I trained a diffusion-based text-to-image model entirely from scratch using only real flower photographs (Oxford Flower-102). No pre-trained checkpoints. No inherited aesthetic priors. Any “artistic” qualities here are not copied from art history; they are grown through constraint.
The method is called procedural style anchoring. After learning to generate flowers from text, the model is fine-tuned on the same photographs after they are transformed by deterministic procedural filters i.e. posterization, Gouache-watercolor, pointillist sampling, mosaic tiling, cross-hatching fields, low-poly abstraction, anisotropic Kuwahara smoothing, and more. These procedures act like a kind of visual physics: they impose consistent rules about edges, texture, and color, and the model internalizes those rules as a stable aesthetic.
The highlight of this work — and the engine of its creative surprise — is ensembling. Instead of relying on one style model at a time, I combine multiple procedurally anchored models during generation using weighted soft blending, sometimes block-wise across the network. Different “style instincts” can influence different parts of the diffusion process, allowing hybrid aesthetics to emerge: halftone structure with fauvist color, mosaic geometry with painterly softness, felt-like texture fused with poster-flat tonal fields. The result is not a simple average, but an interference pattern where new visual dialects appear between established styles.
More detailed approach used in making the ensemble is given after the 1st Gallery section. I tried to limit the technicallity of the description as this page focuses on the art and aesthetics.
Code of implementation is available on GitHub.
"Can a model grow a recognizable “art style” without learning from human artworks — purely from rules, constraints, and the dynamics of generation? Browse slowly. Some images demonstrate single anchored styles; others embrace the ensemble hybrids where the most unexpected forms bloom. Enjoy viewing!"









How do we train a model to learn an art style without art data? How do we ensemble multiple models to create new styles? ⤵ (click for more...)
Here are some examples of original data samples (photos from Flower-102) used to train the models.

The prompt is standardized across all images in this gallery for a fair benchmark.
Prompt used: "a {flower_name} in the wild, in {art_style} painting style"















Two techniques of crossing the block-wise layers were employed: soft-blend and hard-voting using a mix-plan. ⤵ (click for more...)
Soft-blend
Only blocks with cross-attention (e.g., CrossAttnDownBlock2D, mid_block if cross-attn, and CrossAttnUpBlock2D) were soft-blended. For example, in the case of [Soft-blend Oil 0.30/Poster 0.25/Felt 0.45]:
By restricting soft blending to cross-attention blocks, we are mixing models primarily in the components that perform text-guided feature modulation (semantic/style binding), while leaving the rest of the convolutional/residual machinery largely intact (often from a single base model).
Mix-Plan (hard-voting)
All the UNet share the same architecture with 4 down blocks, 1 mid block, and 4 up blocks: Ũ = {Down1, Down2, Down3, Down4, Mid, Up1, Up2, Up3, Up4}. The mix plan is a block-wise parameter grafting rule that builds a single composite UNet, Ũ by selecting (hard mixing) which trained model supplies the parameters of each block. For example, in the case of [Post-Impressionism + Poster + Felt, Mix Plan={"down": [0, 1, 0, 2], "mid": 2, "up": [1, 2, 0, 1]}]:
Firstly, it means three independently trained UNets:
Then, the mix plan specifies how to combine these models across different blocks:


















































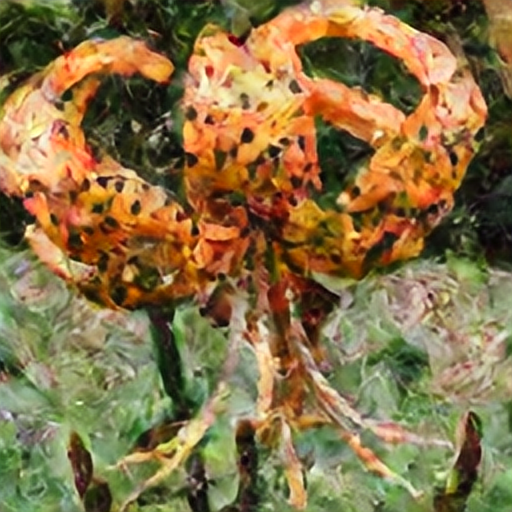


































































The procedural filters in this framework are not the end product; they are controlled supervisory signals. The scientific contribution lies in showing that a generative model can absorb these signals into a text-conditioned image prior that produces novel, style-consistent images from noise, including compositions that no direct filter pipeline could generate.
As the “style prior” in this project is procedural, it’s inherently extensible: richer controlled style priors mean richer constraints. As we move from simple abstractions (posterization, oil, pointillism, mosaic etc.) toward more complex, physically inspired procedures — pigment diffusion, layered glazing, paper granulation, anisotropic brush dynamics, printmaking noise, or even learned procedural operators — the model won’t just imitate a look; it will internalize a deeper mechanism for producing it. Combined with ensemble mixing, these procedures can interact and interfere in increasingly high-dimensional ways, opening a path toward more intricate, hybrid, and previously unseen styles — styles that emerge from controllable visual “physics,” rather than borrowed exemplars.

Kuan Yew, LEONG is a lead researcher and adjunct professor of Computer Vision and Machine Learning based in Kyoto, Japan. Currently, he works on the improvements of computer vision by researching different learning algorithms. Kuan Yew demonstrates a keen interest in the intersection of art, natural science, and technology.
He maintains a forward-thinking perspective, recognizing that present-day challenges represent opportunities for innovation, and is committed to leveraging technological advancements for future betterment.
See more works on his Github: https://github.com/kuanyewleong
Email: kuanyew.leong@gmail.com